Das Subdifferential ist eine Verallgemeinerung des Gradienten auf nicht differenzierbare konvexe Funktionen. Das Subdifferential spielt eine wichtige Rolle in der konvexen Analysis sowie der konvexen Optimierung.
Inhaltsverzeichnis
1Definition
2Anschauung
3Beispiel
4Beschränktheit
4.1Beweis
5Differenzierbarkeit
6Literatur
Definition
Sei eine konvexe Funktion. Ein Vektor heißt Subgradient von an der Stelle , wenn für alle gilt[1]
,
wobei das Standardskalarprodukt bezeichnet.
Das Subdifferential ist die Menge aller Subgradienten von im Punkt .[2]
Existieren die folgenden Grenzwerte
so wird das Intervall aller Subgradienten "das Subdifferential der Funktion bei " genannt und wird als geschrieben.
Für eine konvexe Funktion gilt , für eine nicht konvexe Funktion gilt dies nicht und daher ist .
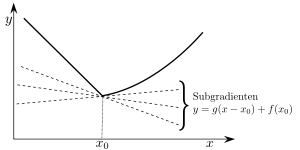
Anschauung
Subgradienten einer konvexen Funktion
Intuitiv bedeutet diese Definition für , dass der Graph der Funktion überall über der Geraden liegt, die durch den Punkt geht und die Steigung besitzt:
Da die Normalengleichung von gerade
ist, ist die Normale an also .
Im allgemeinen Fall liegt über der Hyperebenen, die durch den Fußpunkt und die Normale gegeben ist.
Wegen des Trennungssatzes ist das Subdifferential einer stetigen konvexen Funktion überall nicht leer.
Beispiel
Das Subdifferential der Funktion , ist gegeben durch:
Eine ähnliche Eigenschaft ist bei der Lasso-Regression für die Herleitung der Soft-Threshold-Funktion wichtig.
Beschränktheit
Sei stetig und sei beschränkt. Dann ist die Menge beschränkt.
Beweis
Sei stetig und sei beschränkt. Setze wobei . Angenommen ist nicht beschränkt, dann gibt es für ein und ein mit . Sei . Somit sind . Wir erhalten die Abschätzung
.
ist also kein Subgradient. Das ist ein Widerspruch.










![{\displaystyle [a,b]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/9c4b788fc5c637e26ee98b45f89a5c08c85f7935)
![{\displaystyle \partial f(x_{0}):=[a,b]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/eef8efa37ce03d6bfec0b3806cf42ed102c5ee31)













![{\displaystyle \partial f(x_{0})={\begin{cases}\{-1\}&x_{0}<0\\\left[-1,1\right]&x_{0}=0\\\{1\}&x_{0}>0\end{cases}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/a99132d53aa509f119f4213b458e1ec44ebce038)























